
Google Cloud launches BigLake, a new cross-platform data storage engine – TechCrunch
[ad_1]
At its Cloud Data Summit, Google these days declared the preview start of BigLake, a new info lake storage motor that tends to make it simpler for enterprises to evaluate the data in their data warehouses and facts lakes.
The strategy here, at its main, is to choose Google’s practical experience with functioning and managing its BigQuery facts warehouse and extend it to knowledge lakes on Google Cloud Storage, combining the greatest of knowledge lakes and warehouses into a solitary support that abstracts absent the underlying storage formats and programs.
This knowledge, it’s worthy of noting, could sit in BigQuery or dwell on AWS S3 and Azure Facts Lake Storage Gen2, much too. Via BigLake, developers will get obtain to 1 uniform storage motor and the ability to question the underlying information shops as a result of a solitary process with out the want to move or duplicate info.
“Running information throughout disparate lakes and warehouses makes silos and raises hazard and price, specifically when data requires to be moved,” explains Gerrit Kazmaier, VP and GM of Databases, Details Analytics and Business enterprise Intelligence at Google Cloud, notes in today’s announcement. “BigLake lets firms to unify their data warehouses and lakes to analyze info with out stressing about the fundamental storage format or method, which eliminates the have to have to replicate or move data from a resource and cuts down cost and inefficiencies.”
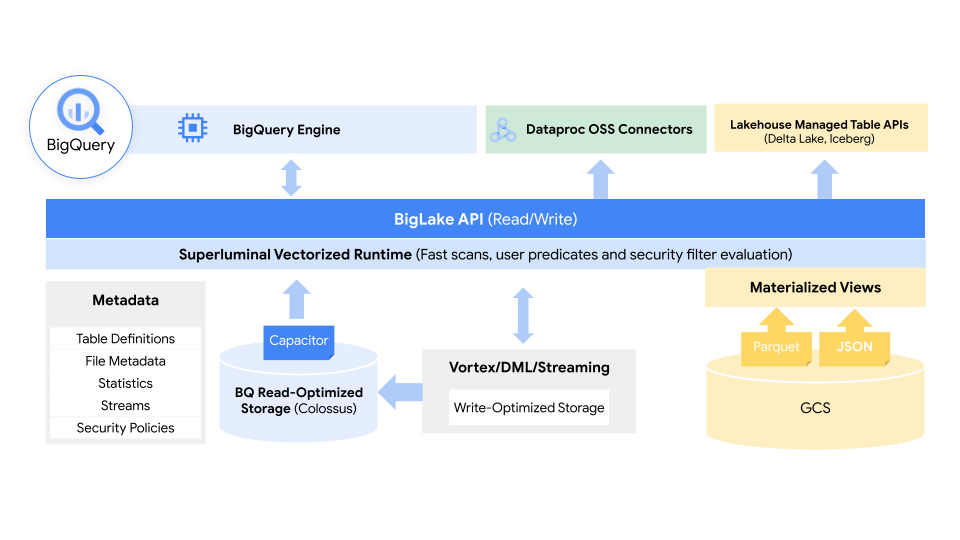
Graphic Credits: Google
Employing plan tags, BigLake makes it possible for admins to configure their stability policies at the desk, row and column amount. This contains data saved in Google Cloud Storage, as perfectly as the two supported 3rd-occasion devices, the place BigQuery Omni, Google’s multi-cloud analytics assistance, enables these stability controls. Those people security controls then also be certain that only the ideal knowledge flows into resources like Spark, Presto, Trino and TensorFlow. The services also integrates with Google’s Dataplex device to provide further details management abilities.
Google notes that BigLake will provide fine-grained obtain controls and that its API will span Google Cloud, as properly as file formats like the open column-oriented Apache Parquet and open-supply processing engines like Apache Spark.
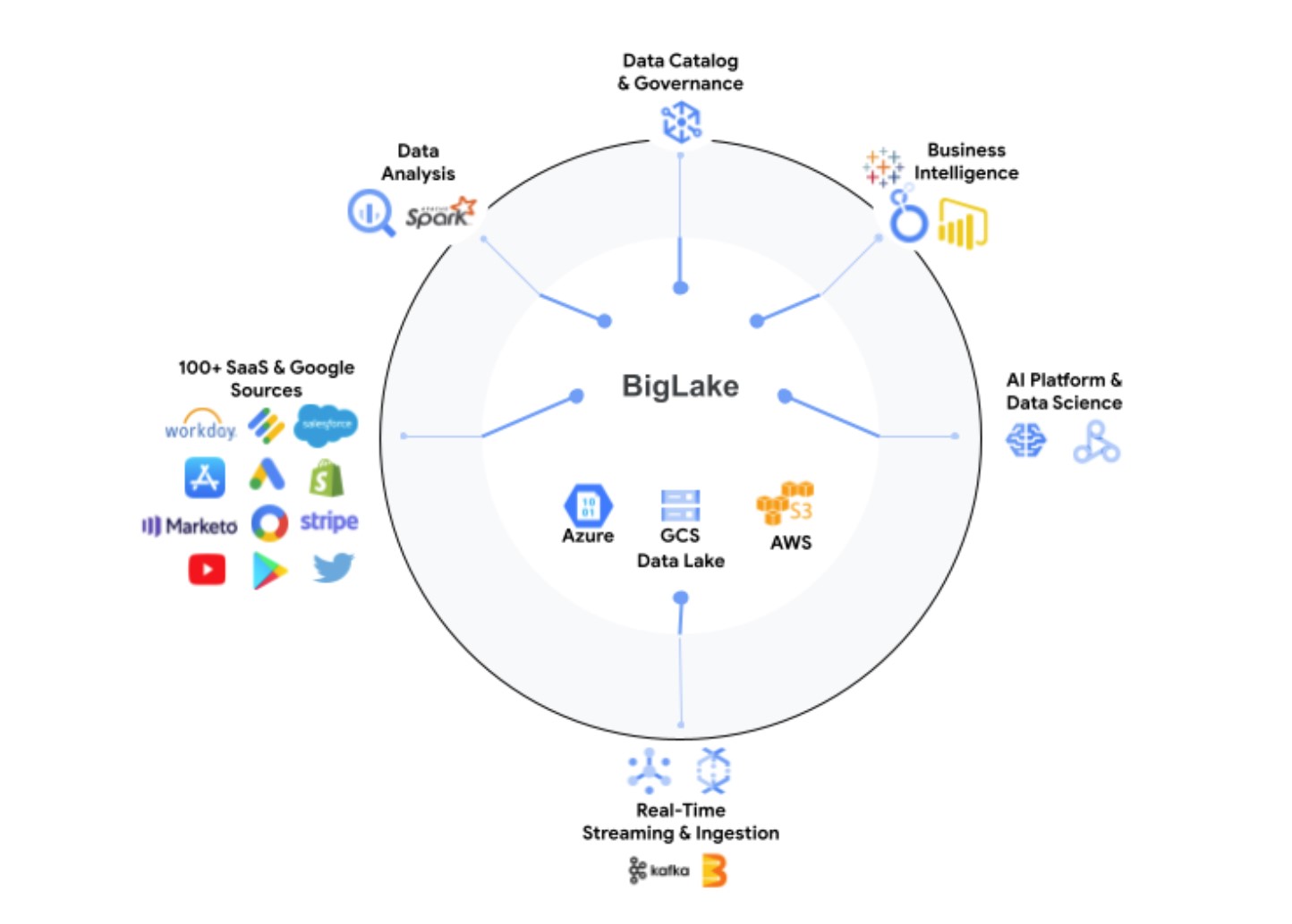
Graphic Credits: Google
“The quantity of precious facts that corporations have to manage and evaluate is developing at an incredible level,” Google Cloud application engineer Justin Levandoski and product supervisor Gaurav Saxena describe in today’s announcement. “This knowledge is progressively dispersed throughout numerous spots, like details warehouses, information lakes, and NoSQL merchants. As an organization’s data receives a lot more complicated and proliferates across disparate facts environments, silos emerge, making greater hazard and price tag, specifically when that info requires to be moved. Our customers have produced it obvious they need to have assist.”
In addition to BigLake, Google also today declared that Spanner, its globally distributed SQL database, will before long get a new element identified as “change streams.” With these, buyers can simply observe any adjustments to a databases in serious time, be all those inserts, updates or deletes. “This assures shoppers generally have accessibility to the freshest knowledge as they can very easily replicate variations from Spanner to BigQuery for serious-time analytics, set off downstream software habits working with Pub/Sub, or retail outlet alterations in Google Cloud Storage (GCS) for compliance,” describes Kazmaier.
Google Cloud also today brought Vertex AI Workbench, a resource for running the total lifecycle of a information science undertaking, out of beta and into typical availability, and introduced Connected Sheets for Looker, as properly as the means to accessibility Looker knowledge models in its Knowledge Studio BI instrument.
[ad_2]
Supply backlink